리눅스나 유닉스에서 I/O 성능을 높이기 위해 sendfile() 시스템 호출을 이용해 "Zero Copy"기술을 사용한다. 자바에서는 어떻게 I/O 성능을 높이는가에 관한 글요약.
2008년에 쓰인 글이며 지금은 대중화 된 방법이다. 원문링크
웹 서버가 정적인 파일을 디스크에서 읽어서 소켓에 쓸때 커널 영역과 어플리케이션 영역간에 데이터 복사와 컨텍스트 전환으로 발생되는 비효율은 Zero Copy로 효율적인 처리를 할 수 있다.
Zero Copy는 디스크에서 소켓으로 데이터를 복사할 때 커널레벨에서 데이터를 복사하는 방식으로 CPU 사용율과 메모리 대역폭 사용도 줄이고 커널 모드와 사용자 모드간 컨텍스트 전환 비용도 줄일 수 있기 때문에 성능이 좋아진다.
자바는 java.nio.channels.FileChannel.transferTo() 메소드를 통해 Zero Copy를 제공 한다.
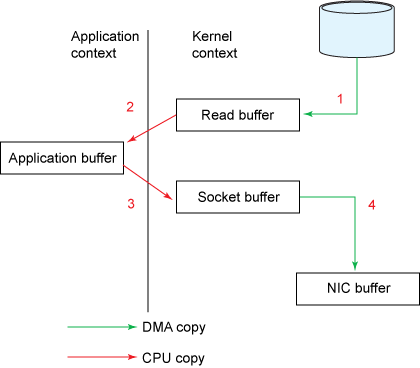
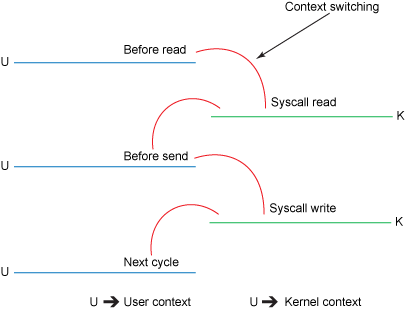
파일에서 데이터를 읽고 소켓에 쓰기까지는 사용자 모드와 커널 모드간 4번의 컨텍스트 전환이 일어난다. 그리고 데이터 복사도 4번 일어난다.
사용자 버퍼에 바로 데이터를 쓰지 않고 "Intermediate kernel buffer"를 사용하는것이 비효율적인것 처럼 보이지만 성능에 더 좋다고 한다. 물론, 데이터를 읽는 쪽에서 커널 버퍼가 "readahead cache"로 동작 하려면 커널 버퍼 크기보다 적은 데이터를 요청해야 하고, 데이터를 쓰는(write) 쪽에서는 비동기로 작업을 완료해야 한다. 커널 버퍼 크기보다 큰 데이터가 요청되면 성능에 병목이 생긴다.
Zero Copy는 이런 불필요한 데이터 복사가 없다.
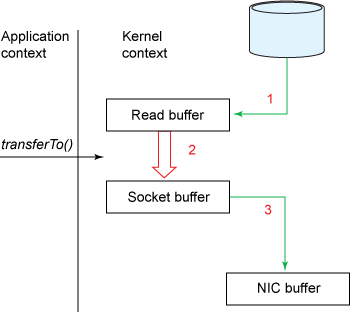
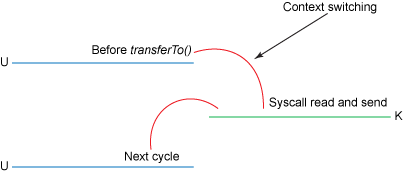
transferTo() 메소드를 사용하면 위 2~3번에 해당하는 데이터 복사가 생기지 않는다.
리눅스 커널 버전이 2.6 인 시스템에서 Traditional vs TransferTo 비교. 대략 65% 시간이 줄어듬
2008년에 쓰인 글이며 지금은 대중화 된 방법이다. 원문링크
웹 서버가 정적인 파일을 디스크에서 읽어서 소켓에 쓸때 커널 영역과 어플리케이션 영역간에 데이터 복사와 컨텍스트 전환으로 발생되는 비효율은 Zero Copy로 효율적인 처리를 할 수 있다.
Zero Copy는 디스크에서 소켓으로 데이터를 복사할 때 커널레벨에서 데이터를 복사하는 방식으로 CPU 사용율과 메모리 대역폭 사용도 줄이고 커널 모드와 사용자 모드간 컨텍스트 전환 비용도 줄일 수 있기 때문에 성능이 좋아진다.
자바는 java.nio.channels.FileChannel.transferTo() 메소드를 통해 Zero Copy를 제공 한다.
데이터를 전송하는 일반적인 방법
파일에서 데이터를 읽고 소켓에 쓰기까지는 사용자 모드와 커널 모드간 4번의 컨텍스트 전환이 일어난다. 그리고 데이터 복사도 4번 일어난다.
- read() 호출은 사용자 모드에서 커널 모드로 컨텍스환트를 전환 하고, DMA( Direct Memorry Access) 엔진이 디스크에서 파일을 읽어 커널 영역 버퍼에 데이터를 저장한다. 이때 첫번째 복사가 생긴다.
- 요청된 양만큼 읽기 버퍼에서 사용자 버퍼로 데이터가 복사되고, read() 호출은 읽은 데이터를 반환한다. 이때 또 한번 컨텍스트 전환이 생기며 데이터는 사용자 영역 버퍼에 저장된다. 두번째 복사.
- 다시 send() 소켓 호출은 사용자 모드에서 커널 모드로 컨텍스트를 전환시키고, 커널 영역 버퍼로 데이터를 복사하는 세번째 복사가 생긴다.
- 완료된 send() 시스템 호출은 값을 반환하고 네번째 컨텍스트 전환이 생긴다. 그리고 DMA 엔진이 커널 영역 버퍼에서 프로토콜 엔진으로 데이터를 복사한다. 네번째 복사.
사용자 버퍼에 바로 데이터를 쓰지 않고 "Intermediate kernel buffer"를 사용하는것이 비효율적인것 처럼 보이지만 성능에 더 좋다고 한다. 물론, 데이터를 읽는 쪽에서 커널 버퍼가 "readahead cache"로 동작 하려면 커널 버퍼 크기보다 적은 데이터를 요청해야 하고, 데이터를 쓰는(write) 쪽에서는 비동기로 작업을 완료해야 한다. 커널 버퍼 크기보다 큰 데이터가 요청되면 성능에 병목이 생긴다.
Zero Copy는 이런 불필요한 데이터 복사가 없다.
Zero Copy 데이터 전송
transferTo() 메소드를 사용하면 위 2~3번에 해당하는 데이터 복사가 생기지 않는다.
- transferTo() 메소드는 DMA 엔진을 통해 읽기 버퍼에 파일 내용을 복사한다. 그러면 데이터는 출력될 소켓과 관련된 커널 버퍼에 복사된다. 복사가 두번 생긴다.
- DMA 엔진이 데이터를 커널 소켓 버퍼에서 프로토콜 엔진으로 복사하면 세번째 복사가 생긴다.
컨텍스트 전환이 4회에서 2회로 줄고 데이터 복사도 4회에서 3회로 줄지만 Zero Copy는 아니다. 리눅스 커널 2.4 이후 커널 파일 디스크립터가 수정되어 네트워크 카드가 gather operation을 지원하면 커널이 중복으로 데이터를 처리하는 것을 줄일 수 있다.
- transferTo() 메소드는 DMA 엔진이 파일 내용을 커널 버퍼로 복사 되게 한다.
- 소켓 버퍼에 데이터가 복사되지 않고 데이터의 위치와 길이등이 기술된 파일 디스크립터가 소켓 버퍼에 추가된다. 그리고 DMA 엔진은 커널 버퍼에서 프로토콜 버퍼로 데이터를 직접 전달한다.
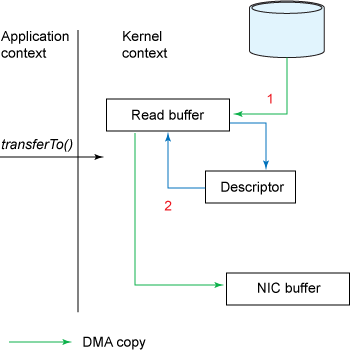 |
| transferTo() 와 gather operation이 사용될때 데이터 복사 |
파일서버 구축
성능 비교
리눅스 커널 버전이 2.6 인 시스템에서 Traditional vs TransferTo 비교. 대략 65% 시간이 줄어듬
| File size | Normal file transfer (ms) | transferTo (ms) |
|---|---|---|
| 7MB | 156 | 45 |
| 21MB | 337 | 128 |
| 63MB | 843 | 387 |
| 98MB | 1320 | 617 |
| 200MB | 2124 | 1150 |
| 350MB | 3631 | 1762 |
| 700MB | 13498 | 4422 |
| 1GB | 18399 | 8537 |
궁금해서 질문드려요. 위의 예제가 zero copy로 인해서 성능이 향상된게 맞나요?
답글삭제제가 알기로 zero copy가 애플리케이션 계층에서의 메모리 버퍼를 생략하고 바로
커널에서 read한 데이터를 socket에 write 하는 걸로 알고 있습니다.
단순히 API만 NIO로 바뀐거 아닌가 라는 생각이 들어서요~
ByteBuffer를 사용한 부분도 결국 애플리케이션에서 다시 버퍼를 사용한 것 아닌가요?
오래전에 옮겨놓은 내용이라 다시 읽어 봤습니다.
삭제"위의 예제가 zero copy로 인해서 성능이 향상된게 맞나요" 부분은
zero copy가 아니라 NIO 구현이라서 빠른게 아닌가 하는 질문으로 이해됩니다.
zero copy는 transferTo 에서 구현하고 있기 때문에 TransferToClient가 빠릅니다.
가령, 예제 서버를 TransferToServer나 TraditionalServer 어느 것을 사용해도
100MB 파일전송을 TraditionalClient와 TransferToClient를 비교해 실행해 보면
zero copy(=transferTo)를 사용하는 TransferToClient가 빠르네요
그리고 TransferToServer의 ByteBuffer 부분은 질문 주신 내용이 맞고
원글 쓰신분이 제로카피를 NIO 구현으로 통일해서 그런거 같습니다